

Upgrade your Asahi Linux systems, because your
graphics drivers are getting a big boost: leapfrogging from OpenGL 2.1 over
OpenGL 3.0 up to OpenGL 3.1! Similarly, the OpenGL ES 2.0 support is bumping up
to OpenGL ES 3.0. That means more playable games and more functioning
applications.
Back in December, I teased an early screenshot of SuperTuxKart’s deferred
renderer working on Asahi, using OpenGL ES 3.0 features like multiple render
targets and instancing. Now you too can enjoy SuperTuxKart with advanced
lighting the way it’s meant to be:
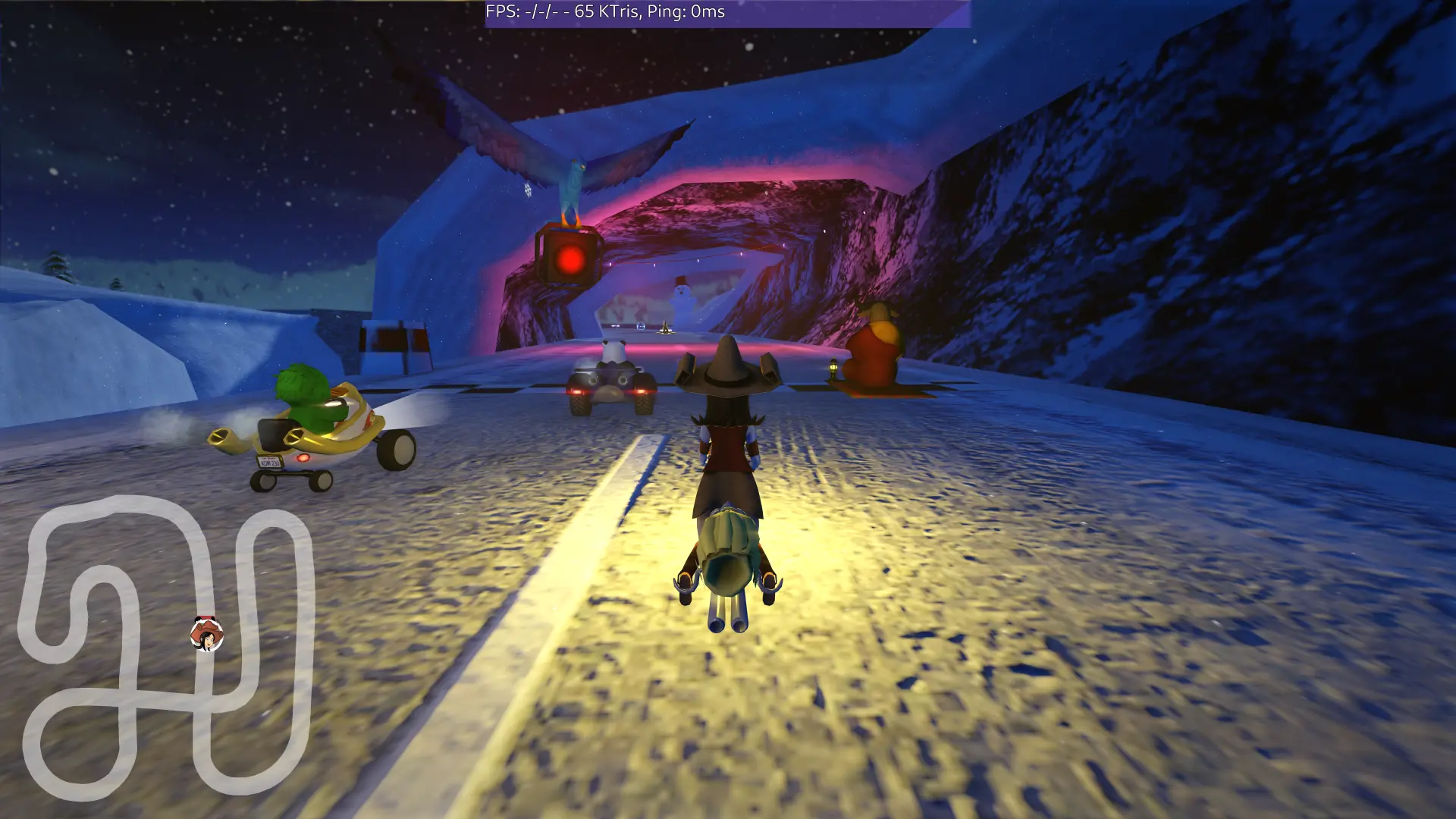
SuperTuxKart rendering with advanced light
As before, these drivers are experimental and not yet conformant to the OpenGL
or OpenGL ES specifications. For now, you’ll need to run our -edge packages
to opt-in to the work-in-progress drivers, understanding that there may be
bugs. Please refer to our previous
post
explaining how to install the drivers and how to report bugs to help us
improve.
With that disclaimer out of the way, there’s a LOT of new functionality packed
into OpenGL 3.0, 3.1, and OpenGL ES 3.0 to make this release. Highlights
include:
- Multiple render targets
- Multisampling
- Transform feedback
- Texture buffer objects
- ..and more.
For now, let’s talk about…
Multisampling
Vulkan and OpenGL support multisampling, short for multisampled
anti-aliasing. In graphics, aliasing causes jagged diagonal edges due to
rendering at insufficient resolution. One solution to aliasing is rendering at
higher resolutions and scaling down. Edges will be blurred, not jagged, which
looks better. Multisampling is an efficient implementation of that idea.
A multisampled image contains multiple samples for every pixel. After
rendering, a multisampled image is resolved to a regular image with one
sample per pixel, typically by averaging the samples within a pixel.
Apple GPUs support multisampled images and framebuffers. There’s quite a bit of
typing to plumb the programmer’s view of multisampling into the form understood
by the hardware, but there’s no fundamental incompatibility.
The trouble comes with sample shading. Recall that in modern graphics, the
colour of each fragment is determined by running a fragment shader given by
the programmer. If the fragments are pixels, then each sample within that pixel
gets the same colour. Running the fragment shader once per pixel still benefits
from multisampling thanks to higher quality rasterization, but it’s not as good
as actually rendering at a higher resolution. If instead the fragments are
samples, each sample gets a unique colour, equivalent to rendering at a higher
resolution (supersampling). In Vulkan and OpenGL, fragment shaders generally
run per-pixel, but with “sample shading”, the application can force the
fragment shader to run per-sample.
How does sample shading work from the drivers’ perspective? On a typical GPU,
it is simple: the driver compiles a fragment shader that calculates the colour
of a single sample, and sets a hardware bit to execute it per-sample instead of
per-pixel. There is only one bit of state associated with sample shading. The
hardware will execute the fragment shader multiple times per pixel, writing out
pixel colours independently.
Easy, right?
Alas, Apple’s “AGX” GPU is not typical.
AGX always executes the shader once per pixel, not once per sample, like older
GPUs that did not support sample shading. AGX does support it, though.
How? The AGX instruction set allows pixel shaders to output different colours
to each sample. The instruction used to output a colour1 takes a set of samples to
modify, encoded as a bit mask. The default all-1’s mask writes the same value
to all samples in a pixel, but a mask setting a single bit will write only the
single corresponding sample.
This design is unusual, and it requires driver backflips to translate “fragment
shaders” into hardware pixel shaders. How do we do it?
Physically, the hardware executes our shader once per pixel. Logically, we’re
supposed to execute the application’s fragment shader once per sample. If we
know the number of samples per pixel, then we can wrap the application’s shader
in a loop over each sample. So, if the original fragment shader is:
interpolated colour=interpolate at current sample(input colour);
output current sample(interpolated colour);
then we will transform the program to the pixel shader:
for (sample=0; sample The original fragment shader runs inside the loop, once per sample. Whenever it
interpolates inputs at the current sample position, we change it to instead
interpolate at a specific sample given by the loop counter sample. Likewise,
when it outputs a colour for a sample, we change it to output the colour to the
single sample given by the loop counter.
If the story ended here, this mechanism would be silly. Adding
sample masks to the instruction set is more complicated than a single bit to
invoke the shader multiple times, as other GPUs do. Even Apple’s own Metal
driver has to implement this dance, because Metal has a similar approach to
sample shading as OpenGL and Vulkan. With all this extra complexity, is there a
benefit?
If we generated that loop at the end, maybe not. But if we know at compile-time
that sample shading is used, we can run our full optimizer on this sample loop.
If there is an expression that is the same for all samples in a pixel, it can
be hoisted out of the loop.2 Instead of
calculating the same value multiple times, as other GPUs do, the value can be
calculated just once and reused for each sample. Although it complicates the
driver, this approach to sample shading isn’t Apple cutting corners. If we
slapped on the loop at the end and did no optimizations, the resulting code
would be comparable to what other GPUs execute in hardware. There might be
slight differences from spawning fewer threads but executing more control flow
instructions3, but that’s minor. Generating the loop early and running the optimizer
enables better performance than possible on other GPUs.
So is the mechanism only an optimization? Did Apple stumble on a better
approach to sample shading that other GPUs should adopt? I wouldn’t be so sure.
Let’s pull the curtain back. AGX has its roots as a mobile GPU intended for
iPhones, with significant PowerVR heritage. Even if it powers Mac Pros today,
the mobile legacy means AGX prefers software implementations of many features
that desktop GPUs implement with dedicated hardware.
Yes, I’m talking about blending.
Blending is an operation in graphics APIs to combine the fragment shader
output colour with the existing colour in the framebuffer. It is usually used
to implement alpha blending,
to let the background poke through translucent objects.
When multisampling is used without sample shading, although the fragment
shader only runs once per pixel, blending happens per-sample. Even if the
fragment shader outputs the same colour to each sample, if the framebuffer
already had different colours in different samples, blending needs to happen
per-sample to avoid losing that information already in the framebuffer.
A traditional desktop GPU blends with dedicated hardware. In the
mobile space, there’s a mix of dedicated hardware and software. On AGX,
blending is purely software. Rather than configure blending hardware, the
driver must produce variants of the fragment shader that include
instructions to implement the desired blend mode. With alpha
blending, a fragment shader like:
colour=calculate lighting();
output(colour);
becomes:
colour=calculate lighting();
dest=load destination colour;
alpha=colour.alpha;
blended=(alpha * colour) + ((1 - alpha) * dest));
output(blended);
Where’s the problem?
Blending happens per sample. Even if the application intends to run
the fragment shader per pixel, the shader must run per sample for
correct blending. Compared to other GPUs, this approach to blending would
regress performance when blending and multisampling are enabled but sample
shading is not.
On the other hand, exposing multisample pixel shaders to the driver solves the
problem neatly. If both the blending and the multisample state are known, we
can first insert instructions for blending, and then wrap with the sample loop.
The above program would then become:
for (sample=0; sample In this form, the fragment shader is asymptotically worse than the application
wanted: the fragment shader is executed inside the loop, running per-sample
unnecessarily.
Have no fear, the optimizer is here. Since colour is the same for each sample
in the pixel, it does not depend on the sample ID. The compiler can move the
entire original fragment shader (and related expressions) out of the per-sample
loop:
colour=calculate lighting();
alpha=colour.alpha;
inv_alpha=1 - alpha;
colour_alpha=alpha * colour;
for (sample=0; sample Now blending happens per sample but the application’s fragment shader runs just
once, matching the performance characteristics of traditional GPUs. Even
better, all of this happens without any special work from the compiler. There’s
no magic multisampling optimization happening here: it’s just a loop.
By the way, what do we do if we don’t know the blending and multisample state
at compile-time? Hope is not lost…
…but that’s a story for another day.
What’s next?
While OpenGL ES 3.0 is an improvement over ES 2.0, we’re not done. In my
work-in-progress branch, OpenGL ES 3.1 support is nearly finished, which will
unlock compute shaders.
The final goal is a Vulkan driver running modern games. We’re a while away, but
the baseline Vulkan 1.0 requirements parallel OpenGL ES 3.1, so our work
translates to Vulkan. For example, the multisampling compiler passes described
above are common code between the drivers. We’ve tested them against OpenGL,
and now they’re ready to go for Vulkan.
And yes, the team is already working on Vulkan.
Until then, you’re one pacman -Syu away from enjoying OpenGL 3.1!
Alyssa Rosenzweig · 2023-06-06



