

Microsoft has shown off its latest research in text-to-speech AI with a model called VALL-E that can simulate someone’s voice from just a three-second audio sample, Ars Technica has reported. The speech can not only match the timbre but also the emotional tone of the speaker, and even the acoustics of a room. It could one day be used for customized or high-end text-to-speech applications, though like deepfakes, it carries risks of misuse.
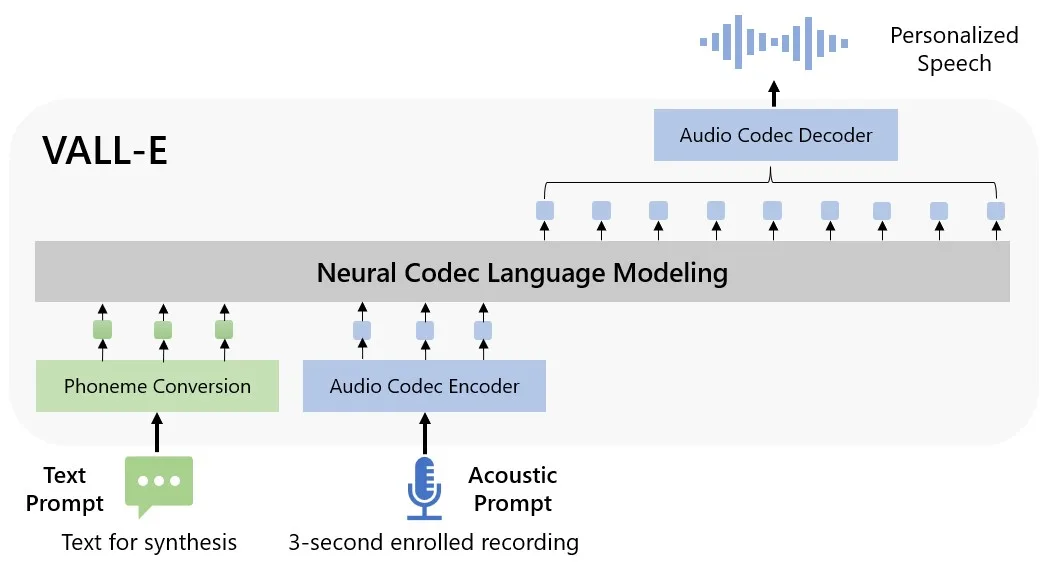
VALL-E is what Microsoft calls a “neural codec language model.” It’s derived from Meta’s AI-powered compression neural net Encodec, generating audio from text input and short samples from the target speaker.
In a paper, researchers describe how they trained VALL-E on 60,000 hours of English language speech from 7,000-plus speakers on Meta’s LibriLight audio library. The voice it attempts to mimic must be a close match to a voice in the training data. If that’s the case, it uses the training data to infer what the target speaker would sound like if speaking the desired text input.
Microsoft
The team shows exactly how well this works on the VALL-E Github page. For each phrase they want the AI to “speak,” they have a three-second prompt from the speaker to imitate, a “ground truth” of the same speaker saying another phrase for comparison, a “baseline” conventional text-to-speech synthesis and the VALL-E sample at the end.
The results are mixed, with some sounding machine-like and others being surprisingly realistic. The fact that it retains the emotional tone of the original samples is what sells the ones that work. It also faithfully matches the acoustic environment, so if the speaker recorded their voice in an echo-y hall, the VALL-E output also sounds like it came from the same place.
To improve the model, Microsoft plans to scale up its training data “to improve the model performance across prosody, speaking style, and speaker similarity perspectives.” It’s also exploring ways to reduce words that are unclear or missed.
Microsoft elected to not make the code open source, possibly due to the risks inherent with AI that can put words in someone’s mouth. It added that it would follow its “Microsoft AI Principals” on any further development. “Since VALL-E could synthesize speech that maintains speaker identity, it may carry potential risks in misuse of the model, such as spoofing voice identification or impersonating,” the company wrote in the “Broader impacts” section of its conclusion.
All products recommended by Engadget are selected by our editorial team, independent of our parent company. Some of our stories include affiliate links. If you buy something through one of these links, we may earn an affiliate commission. All prices are correct at the time of publishing.



